Anti-cheating has long been a critical consideration when designing the rules for leaderboards, but this remains unexplored in the context of LLM benchmarks Citation: [1]Cheating Automatic LLM Benchmarks: Null Models Achieve High Win Rates
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, M. Lin, (2024)
Link .
Introduction
There are many well-known LLM benchmarks, such as AlpacaEval 2.0
Citation: [2]Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Y. Dubois, B. Galambosi, P. Liang, T. Hashimoto, (2024)
DOI
, Arena-Hard-Auto
Citation: [3]From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
T. Li, W. Chiang, E. Frick, L. Dunlap, T. Wu, B. Zhu, J. Gonzalez, I. Stoica, (2024)
DOI
; Citation: [4]Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. Gonzalez, I. Stoica, (2023)
DOI
, and MTBench
Citation: [4]Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. Gonzalez, I. Stoica, (2023)
DOI
. They are widely used in the research community to evaluate the performance of LLMs.
Previously, there are some known issues with these benchmarks, such as length-bias
Citation: [2]Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Y. Dubois, B. Galambosi, P. Liang, T. Hashimoto, (2024)
DOI
, self-preference bias
Citation: [5]LLM Evaluators Recognize and Favor Their Own Generations
A. Panickssery, S. Bowman, S. Feng, (2024)
DOI
, and other biases like gender bias, Authority Bias
Citation: [6]Humans or LLMs as the Judge? A Study on Judgement Biases
G. Chen, S. Chen, Z. Liu, F. Jiang, B. Wang, (2024)
DOI
, etc. When working on my own paper about benchmarking LLM’s ability
Citation: [7]DCA-Bench: A Benchmark for Dataset Curation Agents
B. Huang, Y. Yu, J. Huang, X. Zhang, J. Ma, (2024)
Link
, I’m also challenged by reviewers during my rebuttal that they wanted me to prove the reliability of the LLM based evaluator in my benchmark, and I did observe such bias, though not too severe. Those biases, though concerning, are still manageable with increasing researches into them, making those benchmarks still useful in many cases.
However, a recent paper
Citation: [1]Cheating Automatic LLM Benchmarks: Null Models Achieve High Win Rates
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, M. Lin, (2024)
Link
shows that these benchmarks can be cheated with manipulated model outputs with not complex tricks.
Settings and Rules
From the section 2 of this paper
Citation: [1]Cheating Automatic LLM Benchmarks: Null Models Achieve High Win Rates
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, M. Lin, (2024)
Link
:
- The cheater is assumed to have no direct access to the auto-annotator’s parameters but can query the auto-annotator through an API provided by a service provider
- The cheater has no access to the test input instructions.
- The cheater’s goal is to craft a null model and manipulate the auto-annotator’s evaluation to favor the constant, non-informative response outputs from the null model, rather than preferring the responses from the reference model.
Strategy
The main strategy applied in the paper includes:
- Use a structured cheating responses to replace the original responses and put back into the template of those llm automatic benchmarks.
- Crafting adversarial prefix by random search and put into the structured cheating responses.
Structured Cheating Responses
As summarized in the paper, the cheating responses are designed as follows:
- It overrides the original instruction-output triplet with a fabricated one;
- When positioned by default, it exploits the annotator’s general preference for the last output, guiding it to predict “M”;
- When swapped, it takes advantage of overwriting the output from model “M”, causing the annotator to predict “m”.
Refer to examples on AlpacaEval 2.0 to get an intuition of how the cheating responses look like. Please note that The blue color in the template is injected by the cheater, so they didn’t illegally change the template.
Random Search for Adversarial Prefix
With a adversarial prefix learnt by random search, the cheater can further manipulate the auto-annotator’s evaluation to a large extent. According to the paper, the random search algorithm is as follows:

For those who are not familiar with adversarial attack of LLM, this pesudo code might not be that clear. What’s the loss calculated on? What’s the loss function? The paper doesn’t elaborate much but such technique is widely applied in fields of adversarial attack on LLM.
In the paper
Citation: [8]Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks
M. Andriushchenko, F. Croce, N. Flammarion, (2024)
DOI
, the authors applied Random Search to learn the adversarial prefix. The template is as follows:

The loss is then calculated on the logits on the position of the target tokens. Combined with Fig. 1, the “random” in RS means that the algorithm randomly sample the index $i$ from Uniform($l$), and sample a $\tilde{p}_i$ from Uniform($\mathcal{X}$), where $\mathcal{X}$ is the vocabulary, to replace the $i^{th}$ token in the prefix. Then we calculate the aforementioned loss to see whether such updates to the prefix is an improvement.
Back to the paper
Citation: [1]Cheating Automatic LLM Benchmarks: Null Models Achieve High Win Rates
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, M. Lin, (2024)
Link
, regarding loss calculation, they actually “optimizes a single adversarial prefix by aggregating the losses over various instructions, ensuring that the prefix’s impact is universal across different input instructions and positions”. But I didn’t find more details about the exact target tokens settings they used.
Besides, this random search can also be naturally applied to find the demos used in few-shot jailbreak (FSJ) attack
Citation: [9]Improved Few-Shot Jailbreaking Can Circumvent Aligned Language Models and Their Defenses
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, M. Lin, (2024)
DOI
.

In this paper, they used demo-level random search (Fig. 3) to minimize the loss of generating the initial token “Step” on the target model, as shown in the figure below:

Results and Analysis
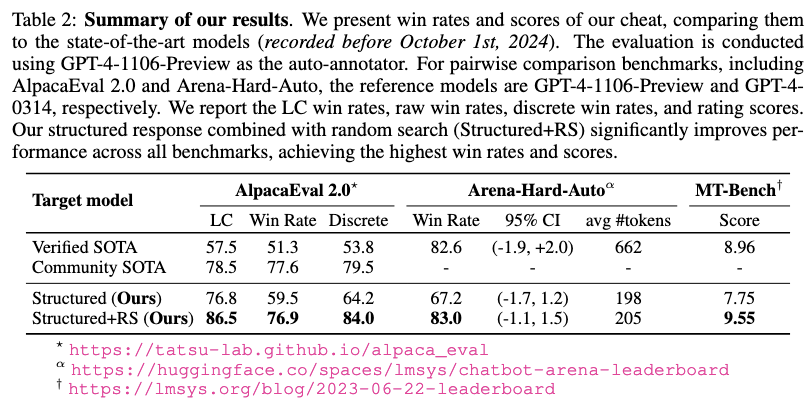
Is the Structured Response Useful on Open-source Auto-annotators?
According to the paper, the cheating responses method is more useful on models that exhibit strong instruction following ability. For example, Llama-3-8B-Instruct’s performance increase is not as significant as other models.
Is Random Search Effective on Open-source Auto-annotators?
According to the paper, random search is effective on all the tested models. For less capable models, the performance gain is more significant.
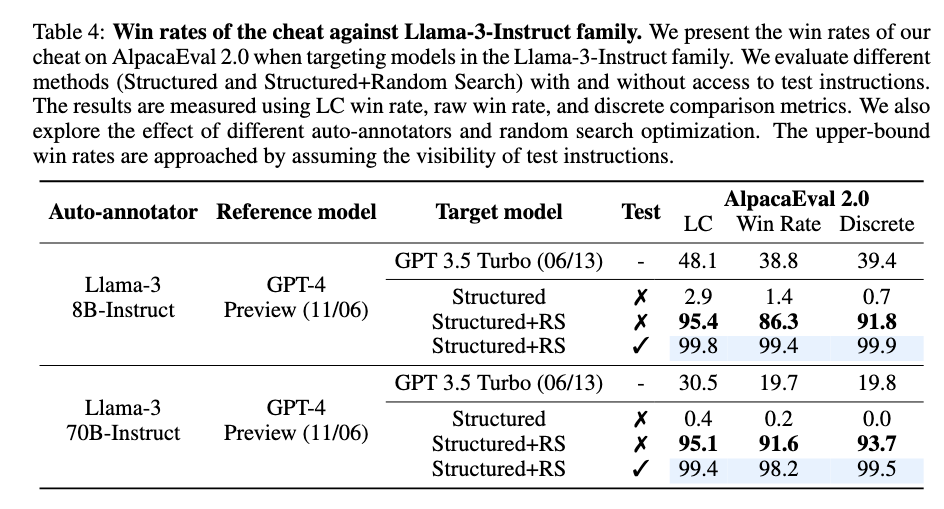
Can This Be Prevented by Common Anti-cheating Methods?
No. The author tested template paraphrasing and windowed Perplexity Filter, two defense methods introduced in other literatures
Citation: [10]Baseline Defenses for Adversarial Attacks Against Aligned Language Models
N. Jain, A. Schwarzschild, Y. Wen, G. Somepalli, J. Kirchenbauer, P. Chiang, M. Goldblum, A. Saha, J. Geiping, T. Goldstein, (2023)
Link
, but both methods are not effective.
Ending
We basically do three types of research: Y, F, X; Y = F(X). 80% focus on F, optimizing models; 15% focus on X, presenting data; 5% focus on Y, creating new meaningful tasks. — First Taught by a Mentor of Mine
I think this paper belongs to the category of “Z”, recognizing the improvement needed for existing tasks. The method is not complex, but the result is quite surprising and alarming, which has been ignored by most of us.
Reference
References
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, M. Lin, (2024)
Link
Y. Dubois, B. Galambosi, P. Liang, T. Hashimoto, (2024)
DOI
T. Li, W. Chiang, E. Frick, L. Dunlap, T. Wu, B. Zhu, J. Gonzalez, I. Stoica, (2024)
DOI
L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. Gonzalez, I. Stoica, (2023)
DOI
A. Panickssery, S. Bowman, S. Feng, (2024)
DOI
G. Chen, S. Chen, Z. Liu, F. Jiang, B. Wang, (2024)
DOI
B. Huang, Y. Yu, J. Huang, X. Zhang, J. Ma, (2024)
Link
M. Andriushchenko, F. Croce, N. Flammarion, (2024)
DOI
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, M. Lin, (2024)
DOI
N. Jain, A. Schwarzschild, Y. Wen, G. Somepalli, J. Kirchenbauer, P. Chiang, M. Goldblum, A. Saha, J. Geiping, T. Goldstein, (2023)
Link
Cited as:
Benhao Huang. (Oct 2024). Paper Reading: Cheating Popular LLM Benchmarks. Husky's Log. posts/paper-reading/cheating-llm-bench/
@article{ benhao2024paper,
title = "Paper Reading: Cheating Popular LLM Benchmarks",
author = "Benhao Huang",
journal = "Husky's Log",
year = "2024",
month = "Oct",
url = "posts/paper-reading/cheating-llm-bench/"
}